For many applications, speed is a critical feature. A slow, lagging AI can frustrate users and hurt adoption. The LLM Latency dashboard provides the tools you need to monitor and optimise the speed of your AI responses.
We provide more than just a simple average. You can analyse:
- Average Latency: The typical response time for each model.
- P95 and P99 Latency: These percentiles show you the worst-case scenarios, helping you understand the experience for the slowest 5% or 1% of requests. This is crucial for building robust, production-grade applications.
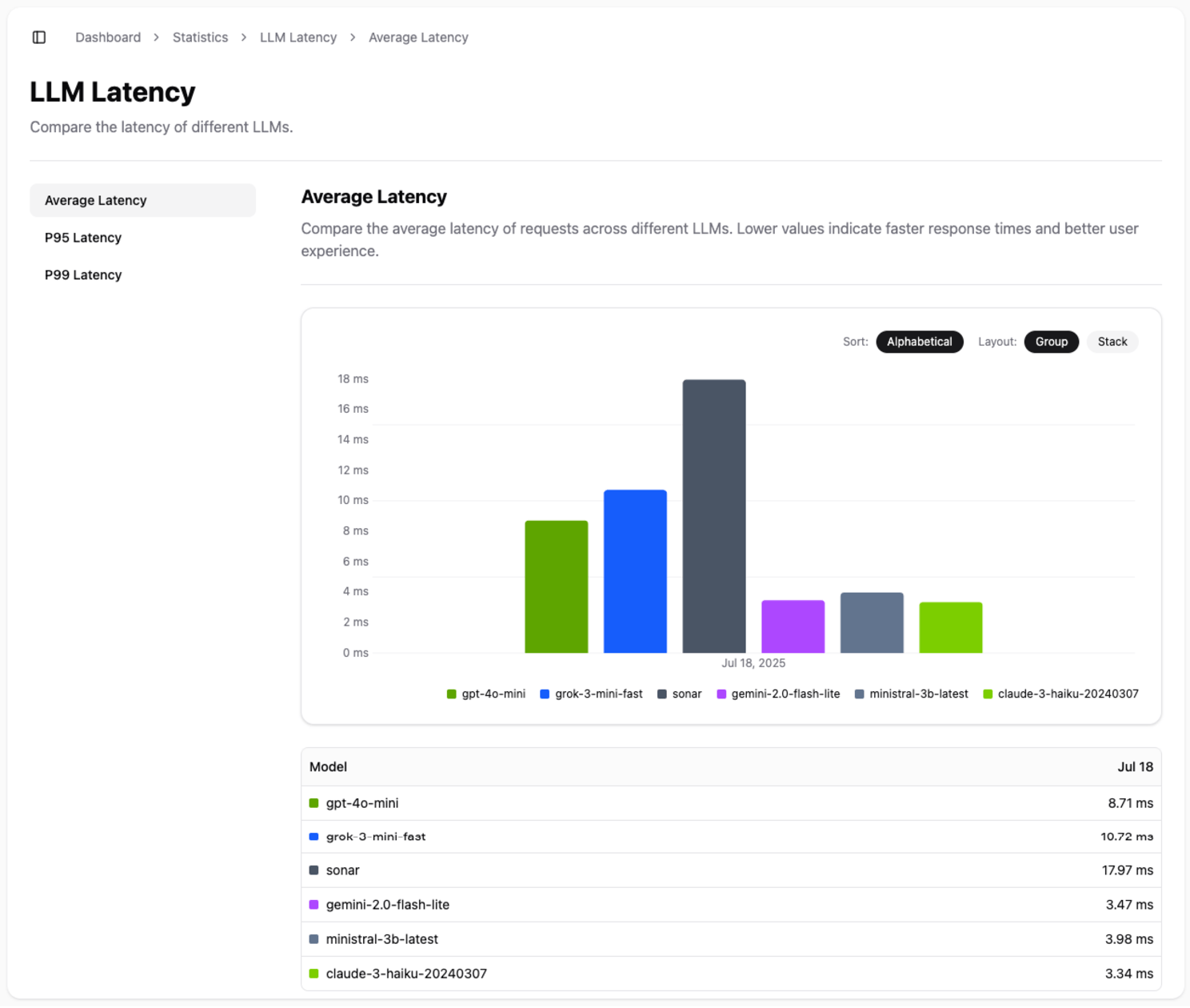
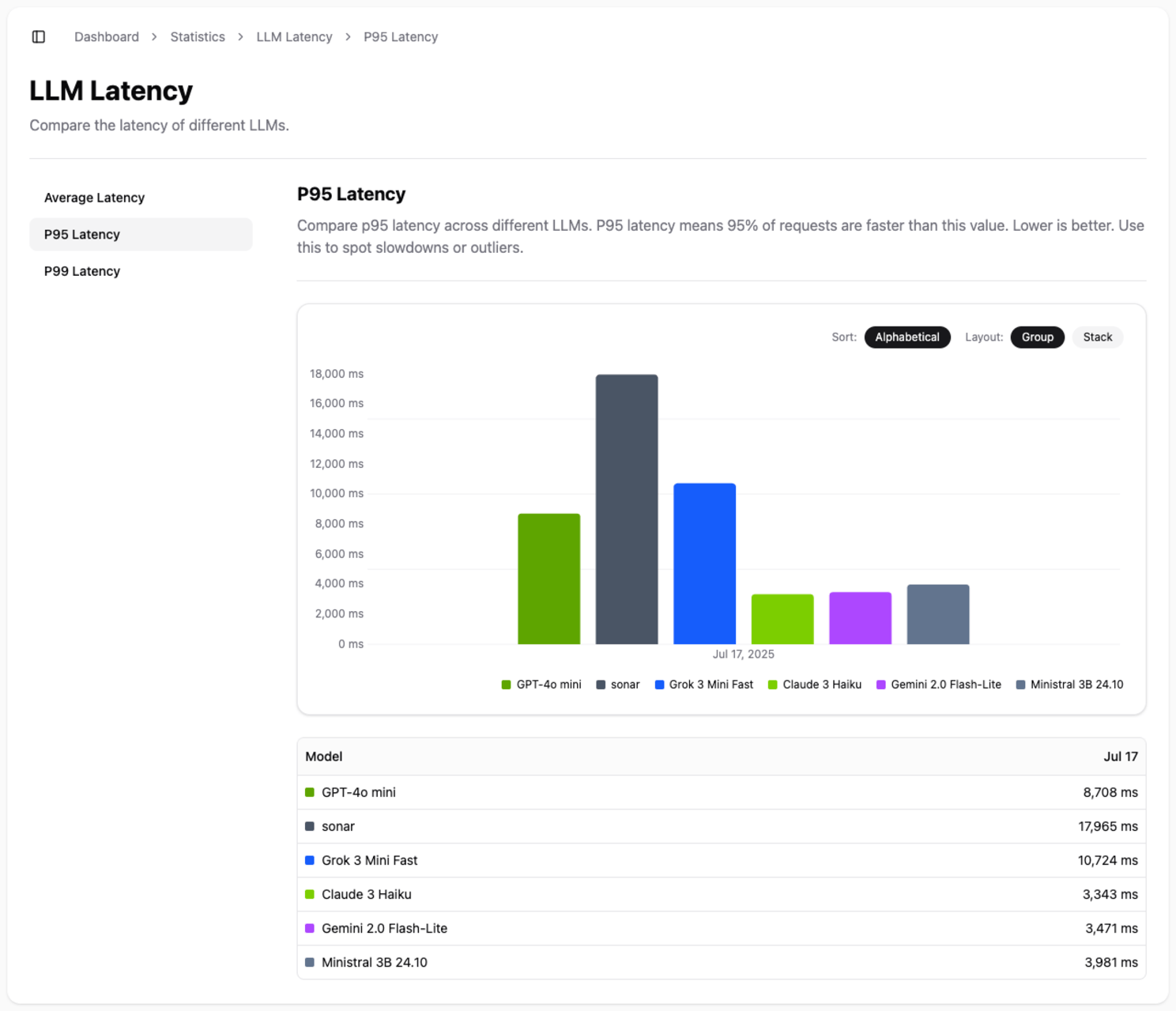
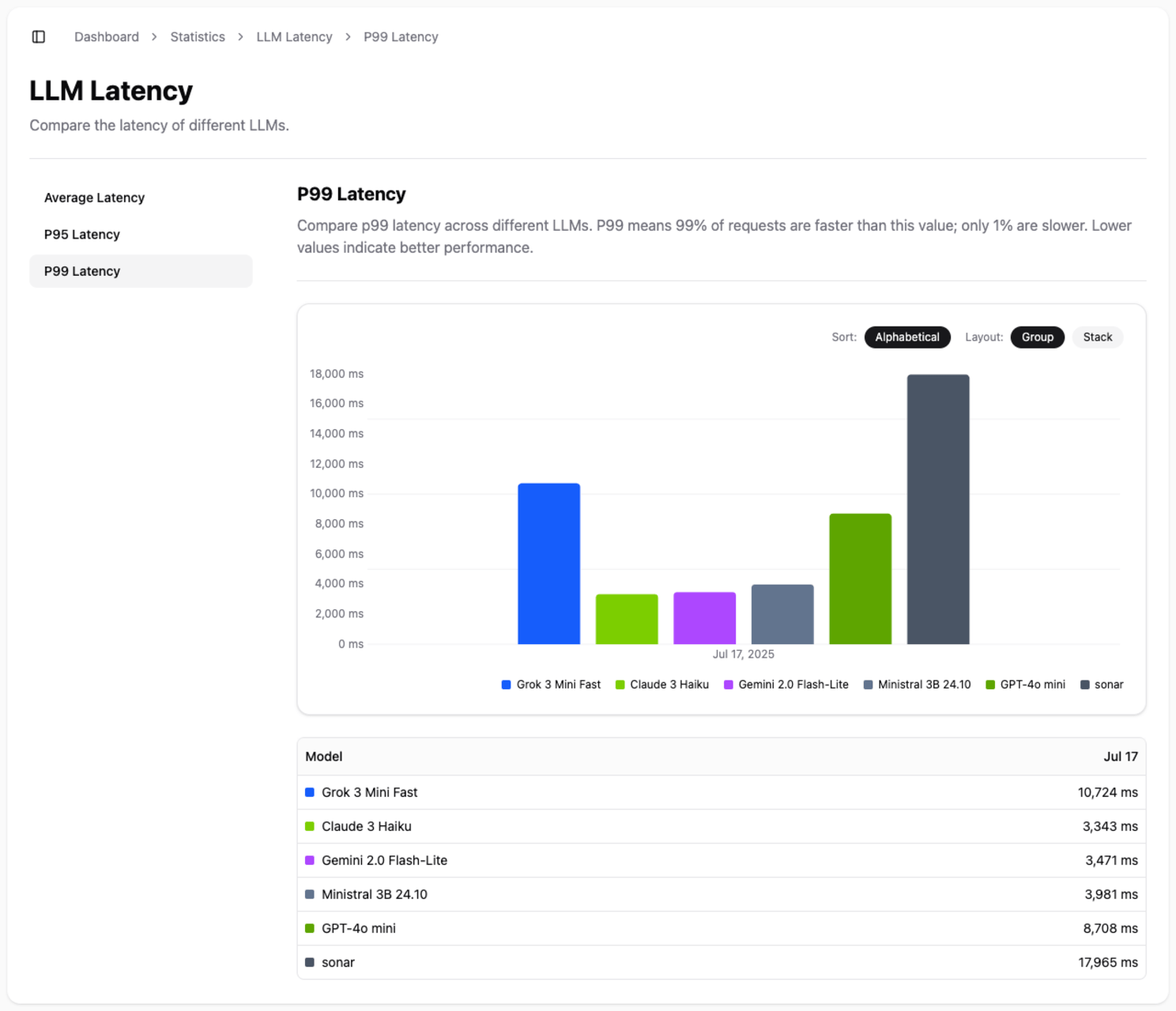
Use this data to select models that meet your performance requirements and deliver a smooth, seamless experience to your end-users.